Working with large datasets (300M) on a tiny machine (512MB RAM, 1 core)

In my previous post I wrote about processing a 300M dataset on my laptop in under 30 seconds with Polars. As I still had the dataset stored on my laptop, I got curious again. What if you are not privileged with a Macbook Pro with an M1 chip and 16GB of RAM? How does Polars perform on this kind of large datasets on machines with less memory and cores to work with?
With the growing size of data that organisations store, it might become harder to do analytics or process it efficiently. You might resort to the cloud, but there is always tension between management and engineering on the return on investment. Outcomes of analytics don’t always result in clear benefits for the organisation (whole different topic to fill a blog with).
We will use smaller machines in this little investigation to see how low we can go (in regards to specs). Polars is so fast because it uses all our CPU cores. Therefore we can expect execution time to increase, as we will have less cores to work with.
It turns out Polars can process the 300M dataset on the smallest droplet of Digital Ocean — 512MB and 1 core — in little over 3 minutes.
Setting a baseline with Pandas
Most people use Pandas to process most of their data. I did the same until not that long ago. So how does Pandas handle this large dataset? I ran the Pandas query from the TPCH benchmark on my Macbook.
Unfortunately, we will never know how long the query would run on the full dataset with 300M rows. The process got killed shortly after my Macbook already swapped a whopping 34GB of data to SSD.

I downscaled the generated dataset to scale factor 10. This scale factor creates a lineitem file of 2.08GB — 60 million rows. Pandas took a total of 4.24 minutes (most of the time 3.95 minutes went to reading the parquet file) to process the query. And it still swapped 4.97GB of data to the SSD. Without it, the process would have also been killed.

In comparison, Polars ran query 1 on the 300M dataset in 13.7 seconds (see my previous post) on my Macbook. That is 5 times more data in a fraction of the time.
Race to the bottom
As stated, we are using the first query of the TPCH benchmark. It has a nice groupby and aggregations.
Important to use
streaming=Truewhen you collect the results. Otherwise your machine will run out of memory.
The lineitem file, that we scan in our Polars experiment, contains just over 300M rows and is 10.52GB in size. See my previous post if you want to generate the file yourself.
Virtual hardware
Digital Ocean offers several droplets (VMs) sizes. Azure, GCP and AWS offer more flavours, but the ones of Digital Ocean will serve there purpose for our little experiment.
- 4 CPU, 8GB RAM
- 2CPU, 4GB RAM
- 2CPU, 2GB RAM
- 1CPU, 2GB RAM
- 1CPU, 1GB RAM
- 1CPU, 512MB RAM
I have written the parquet file to an additional volume that I connected to the droplets. That way I didn’t have to generate the dataset over and over again.
Results
Below is the overview of how long the query took on each machine to process the dataset.
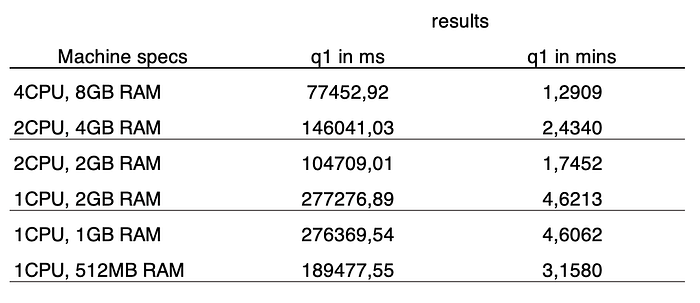
On my laptop I could process this query in around 13.7 seconds. The performance drop is mainly due to having less cores available to process the data. This becomes clear when we look at the results.
It is fascinating to see that Polars is so efficient and can process our dataset with only 512MB RAM. In theory you could trade your expensive laptop for a Raspberry Pi (or use a €4 a month VM) + Polars, and still be faster than your workflow with Pandas..
Conclusion
Polars is not only blazingly fast on high end hardware, it still performs when you are working on a smaller machine. The results of Pandas show why many organisations and professionals switch to cloud solutions to process larger datasets. Polars show that this is not immediately necessary. Nowadays you can work on your laptop for datasets of any size to do most of the data processing work.
Learn more about Polars here: www.github.com/pola-rs/polars
